CSV stands for “Comma-Separated Values,” but in reality, not all CSVs use commas. Many use semicolons, tabs, or even pipes to separate columns. Encoding differences, decimal separators, and regional formats also create inconsistencies that make importing or analyzing CSVs tricky.
At CSV Loader, we frequently see developers and analysts struggle with files that appear “correct” but fail to load properly because of these variations. For example, a European CSV might use semicolons and commas differently than a U.S. CSV. A financial CSV might use a comma as a decimal separator, causing numeric parsing errors.
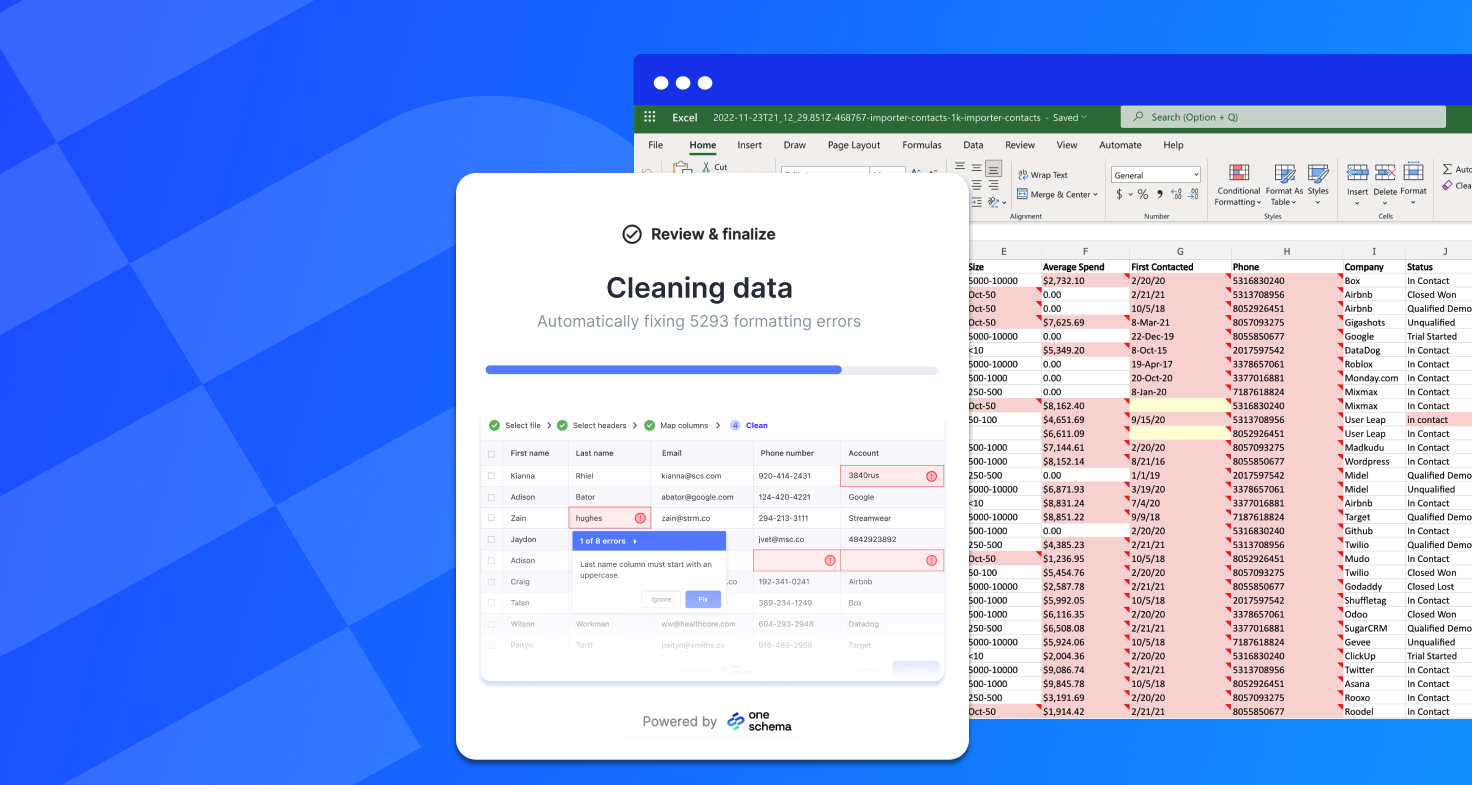
These inconsistencies make CSV validation critical. Tools that detect delimiters, encoding, and header integrity can save hours of frustration. Clear documentation is equally important — even a perfectly formatted CSV is useless if recipients don’t know its structure.
Despite these challenges, CSV’s flexibility is also a strength. Organizations can adapt the format to their needs without strict software requirements. The key is establishing standards within teams or projects to ensure compatibility.
Ultimately, CSV variants show the tension between simplicity and flexibility. While multiple “dialects” exist, proper preparation, validation, and documentation ensure that CSV remains a reliable data exchange format — even across borders and industries.
At CSV Loader, we frequently see developers and analysts struggle with files that appear “correct” but fail to load properly because of these variations. For example, a European CSV might use semicolons and commas differently than a U.S. CSV. A financial CSV might use a comma as a decimal separator, causing numeric parsing errors.
These inconsistencies make CSV validation critical. Tools that detect delimiters, encoding, and header integrity can save hours of frustration. Clear documentation is equally important — even a perfectly formatted CSV is useless if recipients don’t know its structure.
Despite these challenges, CSV’s flexibility is also a strength. Organizations can adapt the format to their needs without strict software requirements. The key is establishing standards within teams or projects to ensure compatibility.
Ultimately, CSV variants show the tension between simplicity and flexibility. While multiple “dialects” exist, proper preparation, validation, and documentation ensure that CSV remains a reliable data exchange format — even across borders and industries.